La motivación para hacer este ejemplo viene de una observación curiosa que se dio al investigar para el capítulo (cap-Pois?).
En la página de Wikipedia sobre los procesos de Poisson puntuales, al hablar de la aleatoriedad espacial completa (CSR), se menciona que la posición de celulares en Sydney, Australia, cumple aproximadamente con la propiedad de ser CSR, comparando con otros territorios. Al revisar el artículo donde se publicó este resultado (Lee, Shih, y Chen 2013), se puede ver que se utilizan herramientas un tanto más complejas que las desarrolladas aquí pero el espíritu es el mismo: examinar la posibilidad de un proceso Poisson espacial.
Un trabajo similar que se revisó es el artículo (Fattori, Groisman, y Sarraute 2018), en el que se hace el estudio en el territorio de Buenos Aires, Argentina. El objetivo de este artículo es comparar distintos estimadores de funciones de intensidad y métodos para probar la propiedad CSR.
6.1 Datos de Sydney
Es imposible replicar el resultado del artículo (Lee, Shih, y Chen 2013) ya que el criterio es distinto. El conjunto de datos utilizado es el cual se recuperó de OpenCellId (versión sin API), que tiene los datos de las torres de celulares hasta el 2024.
El número de torres de celulares registradas en el conjunto de datos para la región de Sydney (aproximada por un rectángulo), tras eliminar datos repetidos y faltantes, es grande \(N=147743\). La distribución de puntos se muestra a continuación.
Código
oceania <-read.csv("Oceania-towers.csv")library(dplyr)library(sf)library(spatstat)library(leaflet)sydney_bbox <-c(lon_min =150.5, lon_max =151.5, lat_min =-34.2, lat_max =-33.5)sydney_towers <- oceania %>%filter( LON >= sydney_bbox["lon_min"] & LON <= sydney_bbox["lon_max"], LAT >= sydney_bbox["lat_min"] & LAT <= sydney_bbox["lat_max"] ) %>%filter(!is.na(LON), !is.na(LAT)) # Eliminar NAsydney_sf <-st_as_sf(sydney_towers, coords =c("LON", "LAT"), crs =4326)sydney_utm <-st_transform(sydney_sf, 32756) # UTM para Sydney (EPSG:32756)coords <-st_coordinates(sydney_utm)sydney_ppp <-as.ppp(coords, W =owin(xrange =range(coords[, "X"]),yrange =range(coords[, "Y"])))plot(sydney_ppp, main ="Distribución de torres celulares en Sydney", pch =20, cex =0.3, cols ="darkblue")
El siguiente mapa interactivo se obtuvo de tomar una muestra uniforme de 1000 de estas torres.
Código
set.seed(123)sydney_sample <- sydney_towers %>%slice_sample(n =1000)leaflet(sydney_sample) %>%addTiles() %>%addCircleMarkers(lng =~LON, lat =~LAT,radius =2,color ="red",popup =~paste("Operador:", Network, "<br>MCC:", MCC, "| MNC:", MNC) ) %>%addControl("Torres celulares en Sydney (muestra de 1000)", position ="topright")
De una inspección visual se puede afirmar que la distribución de torres de celulares tiene regiones en las que se concentra, por lo que un modelo de Poisson homogéneo en toda la región seleccionada no parece apropiado. Esto se puede sustentar con la prueba quadrat.
Código
quadrat_test <-quadrat.test(sydney_ppp, nx =6, ny =6)print(quadrat_test)
Chi-squared test of CSR using quadrat counts
data: sydney_ppp
X2 = 553513, df = 35, p-value < 2.2e-16
alternative hypothesis: two.sided
Quadrats: 6 by 6 grid of tiles
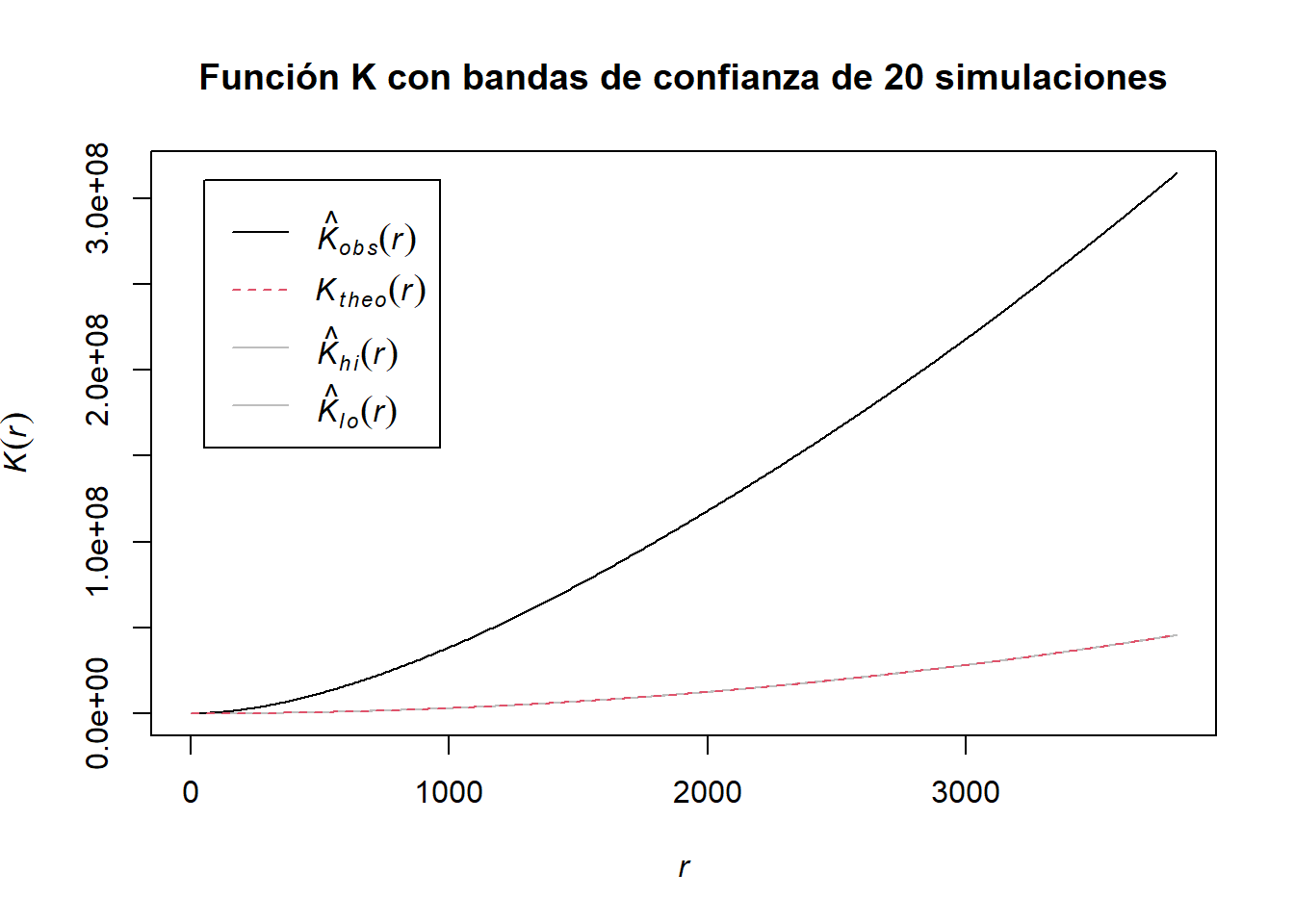
Como el \(p\)-value es prácticamente 0, no existe evidencia que sustente la hipótesis de ser CSR. La función \(K\) de Ripley estimada para estos datos refuerza esta afirmación.
plot(K_env, main ="Función K con bandas de confianza de 20 simulaciones")
Más aún, como se mantiene por arriba de la teórica, existen regiones de agrupamiento en el territorio considerado. Ahora que se verificó que el modelo de CSR no es apropiado, es razonable buscar estimar qué función de intensidad podría describir a estos datos.
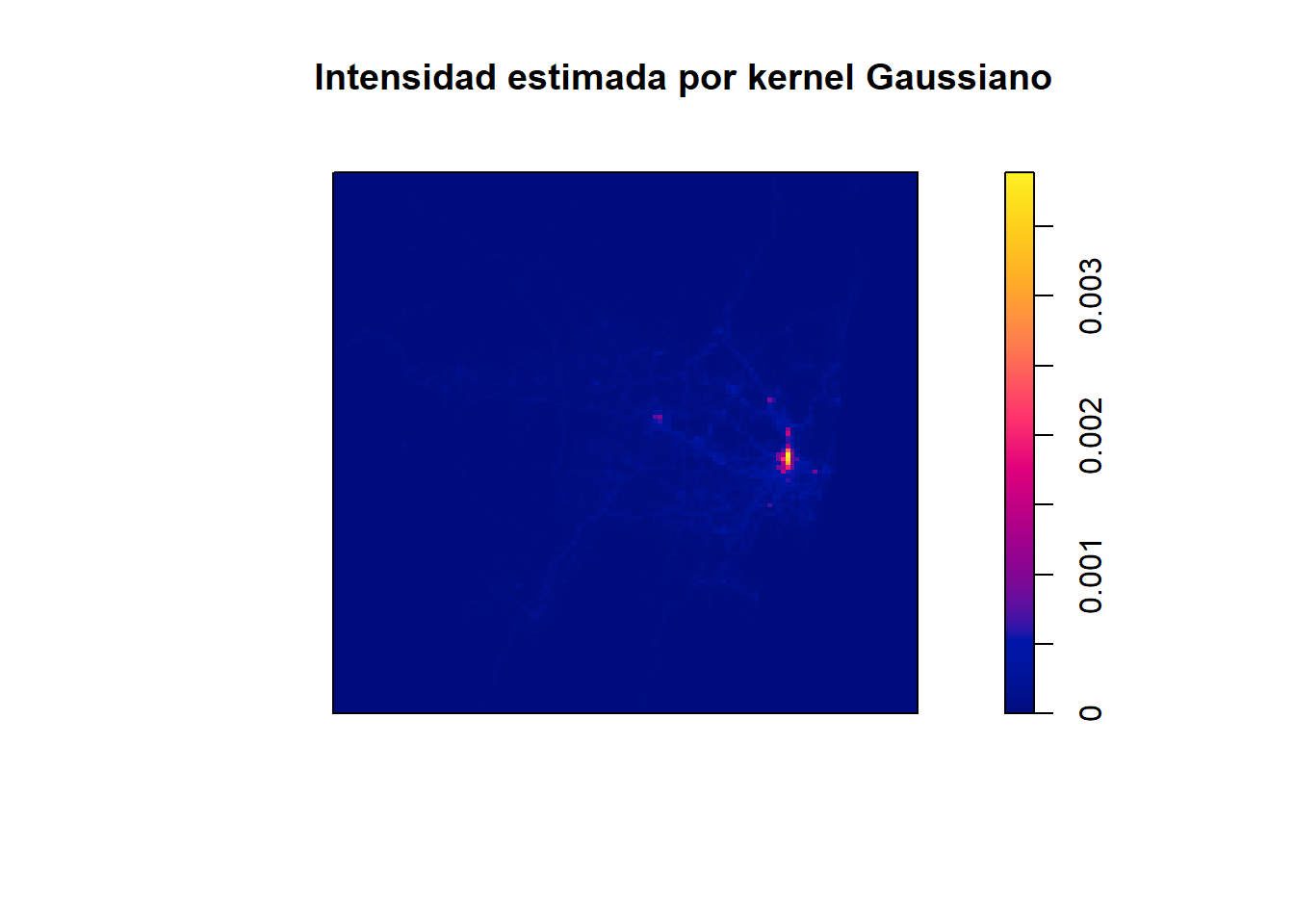
Estimación por kernel. Se utiliza un suavizamiento por kernel Gaussiano a la distribución empírica de la ubicación de los datos. El ancho de banda se elige a partir del criterio de Diggle que está implementado en R.
Código
h_opt <-bw.diggle(sydney_ppp)lambda_kernel <-density(sydney_ppp, sigma = h_opt)plot(lambda_kernel, main ="Intensidad estimada por kernel Gaussiano")
Si bien el campo aproximado para la función de intensidad representa de manera apropiada a la distribución de puntos en el espacio, tiene la desventaja de que los parámetros no son directamente interpretables. Lo destacable es que la parte iluminada de naranja es la parte donde en promedio se concentran más puntos. Revisando un mapa de Sydney, este punto de concentración corresponde a la zona aldeaña a la Universidad de Sydney.
Estimación por modelo Log-Lineal. Para hacer esta regresión Poisson, de la gráfica de la distribución de puntos se puede hacer la observación de que en el centro de la región de estudio están particularmente concentrados los puntos. Elegimos como covariable espacial la distancia al centro, así, si \((x_0,y_0)\) es el centro de la región de estudio, el modelo a ajustar es
Point process model
Fitted to data: sydney_ppp
Fitting method: maximum likelihood (Berman-Turner approximation)
Model was fitted using glm()
Algorithm converged
Call:
ppm.formula(Q = sydney_ppp ~ dist_center)
Edge correction: "border"
[border correction distance r = 0 ]
--------------------------------------------------------------------------------
Quadrature scheme (Berman-Turner) = data + dummy + weights
Data pattern:
Planar point pattern: 147743 points
Average intensity 2.19e-05 points per square unit
Window: rectangle = [267861.8, 353251.7] x [6213018, 6292078] units
(85390 x 79060 units)
Window area = 6750910000 square units
Dummy quadrature points:
770 x 770 grid of dummy points, plus 4 corner points
dummy spacing: 110.8959 x 102.6752 units
Original dummy parameters: =
Planar point pattern: 592904 points
Average intensity 8.78e-05 points per square unit
Window: rectangle = [267861.8, 353251.7] x [6213018, 6292078] units
(85390 x 79060 units)
Window area = 6750910000 square units
Quadrature weights:
(counting weights based on 770 x 770 array of rectangular tiles)
All weights:
range: [113, 11400] total: 6.75e+09
Weights on data points:
range: [113, 5690] total: 4.69e+08
Weights on dummy points:
range: [113, 11400] total: 6.28e+09
--------------------------------------------------------------------------------
FITTED :
Nonstationary Poisson process
---- Intensity: ----
Log intensity: ~dist_center
Model depends on external covariate 'dist_center'
Covariates provided:
dist_center: function(x, y)
Fitted trend coefficients:
(Intercept) dist_center
-8.604571e+00 -8.332562e-05
Estimate S.E. CI95.lo CI95.hi Ztest
(Intercept) -8.604571e+00 5.241220e-03 -8.614843e+00 -8.594298e+00 ***
dist_center -8.332562e-05 2.310248e-07 -8.377842e-05 -8.287282e-05 ***
Zval
(Intercept) -1641.7116
dist_center -360.6783
----------- gory details -----
Fitted regular parameters (theta):
(Intercept) dist_center
-8.604571e+00 -8.332562e-05
Fitted exp(theta):
(Intercept) dist_center
0.0001832662 0.9999166778
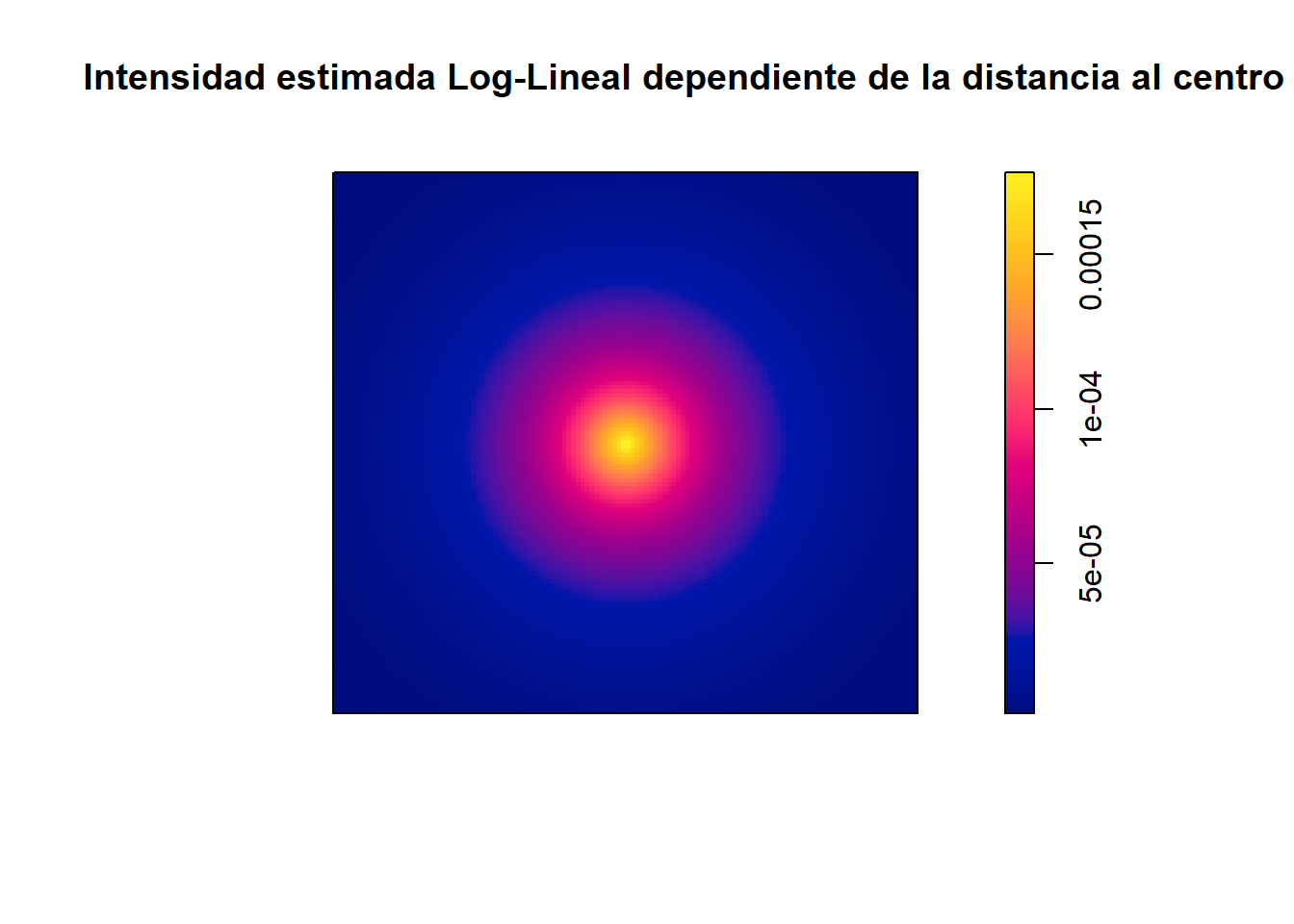
Gráficamente, esta intensidad se puede representar como el siguiente mapa de calor.
Código
plot(predict(model, type ="trend"), main ="Intensidad estimada Log-Lineal dependiente de la distancia al centro")
Combinando la información obtenida de ambos ajustes, se afirma que la intensidad decrece al alejarse del centro, y que en este contexto el centro sería la región cercana a la Universidad de Sydney.
Del mapa interactivo, al revisar la distribución de los puntos, se aprecia que estos puntos están concentrados en zonas habitables. La razón por la cual no se verificó la hipótesis de (Lee, Shih, y Chen 2013) puede ser que la región a considerar no se limitó exclusivamente a la zona habitable de la región. Una revisión a esta técnica de reducir el estudio a calles y casas puede revisarse en (Moraga 2023), donde la función de intensidad se ajusta a nivel calle.
En atención a los comentarios hechos en la sección del proceso Poisson no homogéneo espacial, el proceso de inferencia podría mejorar si se consideraran otro tipo de covariables. En este contexto serían de relevancia variables socioeconómicas.
Fattori, Ezequiel, Pablo Groisman, y Carlos Sarraute. 2018. «Point Process Models for Distribution of Cell Phone Antennas». https://arxiv.org/abs/1807.10975.
Lee, Chia-Han, Cheng-Yu Shih, y Yu-Sheng Chen. 2013. «Stochastic geometry based models for modeling cellular networks in urban areas». Wireless Networks 19. https://doi.org/10.1007/s11276-012-0518-0.
Moraga, Paula. 2023. Spatial Statistics for Data Science: Theory and Practice with R. First. Chapman & Hall/CRC.